
赋予机器感知推断3D对象映射的能力能够帮助人工智能系统更接近对世界的语义理解。所述任务需要构建场景的一致3D对象映射。在名为《ODAM: Object Detection, Association, and Mapping using Posed RGB Video》的论文中,Meta和阿德莱德大学的研究人员探索了一种利用posed RGB video来进行对象检测,关联和映射的方法。
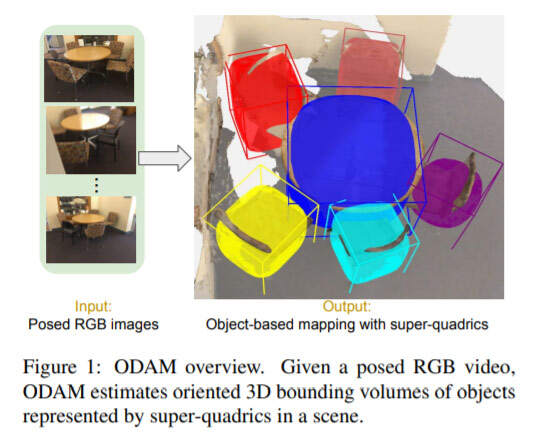
研究人员关注类别级语义重建和对象映射之间的空间,并通过来自姿态RGB帧的3D bounding volume来表示对象。与在图像中使用2D bounding boxs(BBs)类似,3D bounding volume提供了位置和空间的抽象,例如可用于在对象实例锚定信息。
通过诸如NeRF和GRAF等先进方法来可靠地推断场景中单个对象的bounding volume和相关视图是重建、嵌入和描述对象的垫脚石。然而,使用RGB-only视频在3D中定位对象并估计其范围的任务带来了众多挑战。
首先,尽管2D对象检测器的深度学习方法取得了令人印象深刻的成功,但由于透视投影中的深度比例模糊性,其精度受到了影响;其次,关于如何将多视图约束用于3D bounding volume位置和范围的研究和共识很少。
具体而言,3D volume的表示以及如何制定合适的能量函数依然是一个开放的问题;第三,在多视图优化之前需要解决的关键问题是,从不同角度检测单个3D对象实例的关联。与SfM或SLAM不同,不正确的关联会显著地影响3D对象定位。不过,这一问题在杂乱的室内环境中尚未得到充分的研究。在所述环境中,诸如具有几乎相同视觉外观和严重遮挡的多个对象是常见的具体问题。深度模糊和局部观测使数据关联问题复杂化。
针对所述问题,Meta和阿德莱德大学的研究人员提出了ODAM。这是全新的框架结合了深度学习前端和多视图优化后端,并旨在解决来自posed RGB video的3D对象映射问题。与RGB-D相比,RGB-only的优点是功耗显著降低。
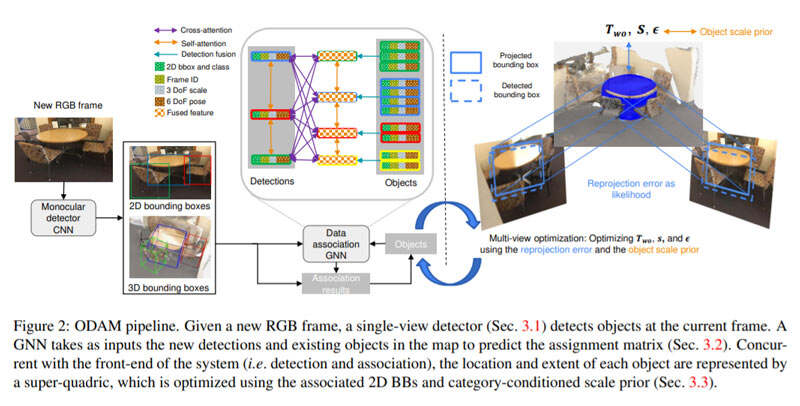
团队假设图像的姿态已知。前端首先检测感兴趣对象,并预测每个对象的2D属性(2D BB,对象类),以及由六自由度刚性姿态和三自由度比例参数化的3D BB,如图2所示。团队指出,RGB-olny方法可以在对象类别的子集中缩小与RGB-D方法的精度差距。
ODAM的目标是在RGB-only图像序列中精确定位对象并估计其bounding volume。如图2所示,给定RGB帧,前端首先检测对象并预测其在camera坐标帧中的2D和3D属性。所述检测与映射中的现有对象实例相关联,或通过使用GNN解决分配问题而成为新的对象实例。鉴于前端的关联性,后端系统优化了来自多个关联2D BB检测的每个对象的超二次曲面表示,以及来自所有关联视图的类别条件对象比例优先级。
其次,GNN中的注意机制不再只考虑手动数据关联方法中的成对关系,而是聚合图中其他节点的信息,从而实现更稳健的匹配。因此,团队的GNN可以从场景中的全套对象推断对象检测的关联,如图2所示。
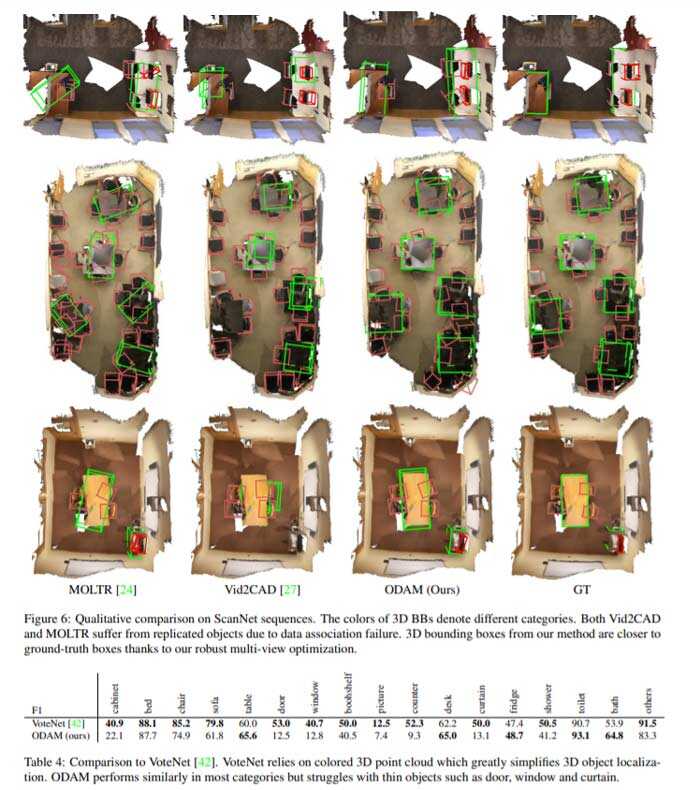
团队使用ScanNet和Scan2CAD来评估对象映射的性能。所有实验均以Nvidia GeForce GTX 1070 GPU运行。单目探测器的运行速度约为10 fps。尽管GNN的推断时间随着映射中对象的数量线性增长,但在所有扫描网验证序列中,GNN的平均运行速度为15 fps。总体而言,ODAM前端可实现约6 fps。使用Pytorch-Adam优化器进行简单的后端优化需要20次迭代,耗时0.2秒。

ODAM的关键在于:(1)attention-based的GNN,用于映射数据关联的鲁棒检测;(2)基于超二次曲面的多视图优化,用于根据关联的2D BB和类观测值精确估计对象bounding volume。
每个检测的3D属性的主要用途是促进新帧和当前全局3D映射之间的数据关联。具体来说,团队开发了一个图形神经网络(GNN),它将当前帧检测的2D和3D属性作为输入,并将它们与映射中现有的对象实例进行匹配。对于现代GPU,系统的前端在杂乱场景中的平均运行速度是6 fps,如ScanNet中的场景。
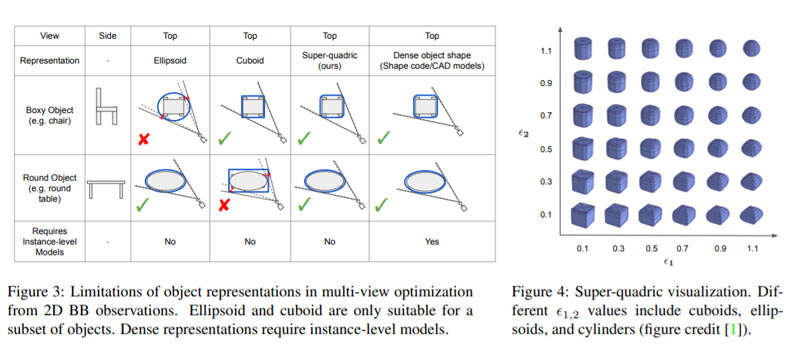
ODAM的后端是一个多视图优化,在给定多个关联的2D BB观测值的情况下,优化每个对象由超二次曲面表示的定向bounding volume。以前的对象集别SLAM框架采用长方体或椭球体作为其对象表示,但它们通常不是通用对象范围的优秀模型。超二次曲面允许长方体和椭球体(以及圆柱体)之间的混合,因此可以为多视图优化提供紧密的bounding volume。
超二次曲面已用于拟合点云数据或使用深度网络从单个图像解析对象形状,而团队提出了一种根据多个2D BB观察值来优化超二次曲面的方法。除此之外,研究人员同时认识到,在杂乱的室内环境中,由于遮挡,对象检测器给出的2D BB不是零误差。团队在优化目标中加入类别条件先验以提高鲁棒性。
使用GNN进行数据关联的优势有两点。首先,可以将不同的属性(例如2D BB、3D BB、对象类)作为网络的联合输入,以提取更具辨别力的特征进行匹配。
总的来说,这份论文的贡献有三个方面:
- 全新的在线3D对象映射系统ODAM,它集成了以6fps速度运行的深度学习前端和基于几何体的后端。ODAM是目前在ScanNet中用于复杂室内场景的性能最好的3D检测和映射纯RGB-only系统;
- 提出了一种将单视图检测与对象级关联的新方法。所述关联采用了一种attention-based的GNN,并将检测的2D和3D属性作为输入;
- 指出了常用的3D bounding volume表示在多视图优化中的局限性,并介绍了一种基于对象尺度先验的超二次曲面优化方法,其与以前的方法相比有明显的改进。
文章来源:映维网



评论