
视觉位置识别VPR是识别特定图像拍摄位置的任务。计算机科学家已经开发了各种深度学习算法来有效地解决这一任务,帮助用户确定在已知环境中捕获图像的位置。
日前,荷兰代尔夫特理工大学介绍了一种新的方法来提高相关深度学习算法的性能。其中,他们提出的方法是基于一种称为连续位置描述符回归CoPR的新模型。团队表示:“我们的研究源于对VPR性能基本瓶颈的反思,以及相关的视觉定位方法。”
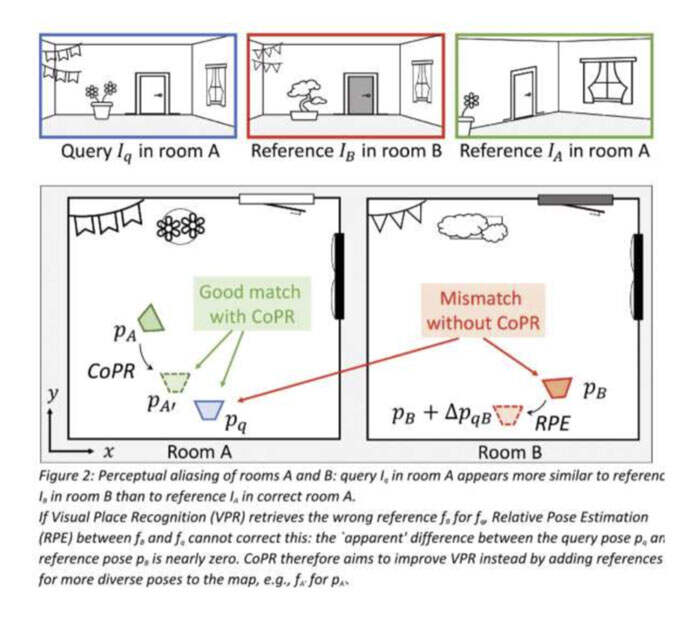
首先,研究人员讨论了“感知混叠”的问题,即具有相似视觉外观的不同区域。举个简单的例子,假设正在收集高速公路最右侧车道的行驶车辆的参考图像。如果稍后针对同一条高速公路的最左侧车道,最准确的VPR估计将是匹配附近的参考图像。然而,视觉内容可能无法正确匹配不同的高速公路路段,因为系统同时会收集在最左侧车道的参考图像。
研究人员发现,克服VPR方法局限性的一种可能方法是训练所谓的图像描述符提取器,并以类似的方式分析图像,而不管它们是在哪个车道拍摄。然而,这将降低他们有效确定照片拍摄地点的能力。
所以,团队希望知道:VPR是否只有在收集每条公路所有车道的图像,或者只在同一车道行驶时才可能实现?他们希望扩展VPR简单而有效的图像检索范例来处理这种实际问题。
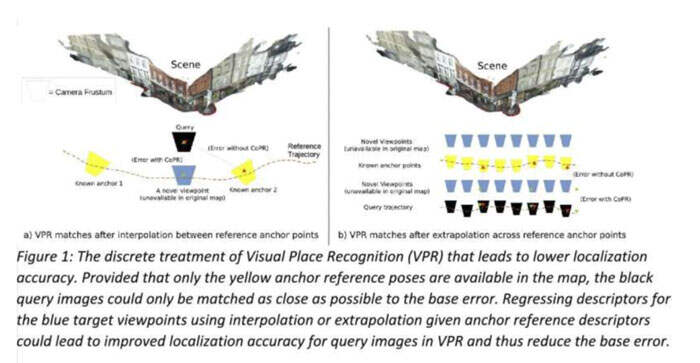
其次,研究人员意识到,即便是一个完美的VPR系统的姿态估计都会受到精度的限制,因为参考图像的有限大小及其姿态意味着映射不能包含每个可能查询的完全相同姿态的参考。
所以,他们认为解决这种稀疏性可能更为重要,而不是尝试建立更好的VPR描述符。
在回顾以前的文献时,团队意识到VPR模型经常会用作更大系统的一部分。例如,SLAM技术可以受益于VPR方法来检测所谓的闭环,而coarse-to-fine定位方法可以通过细化VPR的coarse姿态估计来实现亚米级的定位精度。
研究人员指出:“与这种更复杂的系统相比,VPR可以很好地适用于大型环境,并且易于实现,但它的姿态估计并不那么准确,因为它只能返回之前看到的在视觉上与查询最匹配的图像的姿态。”
尽管如此,SLAM和相对姿态估计确实使用相同的稀疏参考图像和姿态来提供高度准确的姿态估计。那么,这种方法与VPR有何根本不同?
简单来说,这种技术从参考中建立一个连续的空间表示,显式将姿态与视觉特征联系起来,允许从给定参考中插值和外推的姿态来推断视觉内容。
基于观察,研究人员开始探索SLAM和相对姿态估计方法获得的相同连续表征是否可以扩展到单独运行的VPR模型。
传统的VPR方法是将查询图像转换为单个描述子向量,然后与预先计算的描述子进行比较,而coarse-to-fine定位方法则通过细化VPR的粗姿态估计来实现亚米级的定位精度。所有这些引用描述符统称为“映射”。
在比较上述描述符之后,模型确定哪个引用描述符与查询图像的描述符最匹配。因此,通过共享与查询图像描述符最相似的参考描述符的位置和方向(即姿态),模型可以解决VPR任务。
为了提高VPR的定位,团队简单地通过使用深度学习模型来强化描述符的整体映射。他们的方法不是将参考图像的描述符视为与其姿态分离的离散集合,而是将参考图像视为将姿态与其描述符联系起来的潜在连续函数上的点。
研究人员解释道:“如果是一对有两个附近姿态的参考,你可以想象描述符在某种程度上是相似的,因为它们代表相似的视觉内容。不过,它们有些不同,因为它们代表不同的观点。尽管很难手动定义描述符如何准确地变化,但这可以从已知姿态的稀疏可用参考描述符中学习。这就是我们方法的本质:我们可以建模图像描述符如何作为姿态变化的函数而变化,并使用它来致密化参考地图。在离线阶段,我们拟合一个插值和外推函数,可以从附近已知的参考描述符中回归到不可见姿态的描述符。”
完成所述步骤后,团队可以通过添加新姿态的回归描述符来强化VPR模型所考虑的映射。新姿态代表参考图像中相同的场景,但略有移动或旋转。值得注意的是,团队设计的方法不需要对VPR模型进行任何设计更改,并且允许它们在线运行,因为模型提供了更大的参考集,可以匹配查询图像。这种新方法的另一个优点是,它需要相对较小的计算能力。
研究人员指出:“最近的其他研究,例如,神经辐射场和多视点立体遵循了类似的思维过程,同样是尝试在不收集更多参考图像的情况下增加映射的密度。它们提出隐式/显式构建环境的纹理3D模型,以合成新姿态的参考图像,然后通过提取合成参考图像的图像描述符来致密化映射。这种方法与视觉SLAM估计的3D点云相似,需要仔细调整和昂贵的优化。另外,由此产生的VPR描述符可能包括与VPR无关的外观条件(天气、季节等),或者对意外重建伪像过于敏感。”
与以往旨在通过在图像空间中重建场景来提高VPR模型性能的方法相比,代尔夫特理工大学的方法排除了中间图像空间,因为这会增加计算负荷并引入不相关的细节。从本质上讲,团队的方法不是重建这些图像,而是直接在参考描述符上工作。这使得实现大规模的VPR模型要简单得多。
他们补充道:“另外,我们的方法不需要访问参考图像本身,它只需要参考描述符和姿态。有趣的是,我们的实验表明,如果基于深度学习的VPR方法训练为基于姿态相似性的描述符匹配的损失,描述符回归方法最为有效,因为这有助于将描述符空间与视觉信息的几何形状对齐。”
在最初的评估中,尽管所使用的模型非常简单,但研究人员的方法取得了非常喜人的结果。尽管所使用的模型很简单,这意味着更复杂的模型可以很快获得更好的性能。同时,所述方法与现有的相对姿态估计方法的目标非常相似。
他们表示:“这两种方法都解决了不同类型的VPR错误,并且是互补的。相对姿态估计可以进一步减少VPR正确检索参考的最终姿态误差,但如果VPR错误地检索到与真实位置相似的错误位置(感知混叠),则无法固定姿态。我们用现实世界的例子证明,使用我们的方法进行地图致密化可以帮助识别或避免这种灾难性的不匹配。”
在未来,研究小组开发的新方法可以在不增加计算负荷的情况下,帮助提高VPR应用算法的性能。因此,它同时可以提高SLAM或依赖模型的coarse-to-fine定位系统的整体性能。
在接下来的研究中,他们希望设计出更先进的基于学习的插值技术,可以考虑更多的参考文献,因为这可以进一步改进他们的方法。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论