
目前大多数基于VR一体机的Avatar系统都没有下半身,一个重要的原因是,尽管设备能够通过内向外追踪实现头部和双手的动捕,而这又使得估计手臂和胸部的位置相对容易,但系统难以判断你的腿、脚或臀部位置,所以今天的Avatar一直都是缺失下半截。
如果有关注映维网的论文分享,你应该会注意到Meta一直有在进行相关研究,尤其是通过机器学习/深度学习/人工智能等技术来实现基于纯头显摄像头的全身动捕解决方案。
在早前发布的论文《SelfPose: 3D Egocentric Pose Estimation From a Headset Mounted Camera》中,Meta联合伦敦大学学院,布伦瑞克工业大学,马克斯·普朗克智能系统和卡内基梅隆大学等机构探索了基于头显摄像头来进行自我姿态估计的方法。
AR/VR体验需要由用户姿态的显式表征所驱动。特别地,其需要从设备的角度估计用户的姿态,这隐含地对应于以自我为中心的角度,亦即与用户3D头部和身体姿态相应对的“Egopose/自我姿态”。自我姿态驱动着在AR和VR中构建自然体验所需的必要输入。
自我姿态估计是一项具有挑战性的任务。现有的方法通常分为两类:基于非光学传感器的方法和基于摄像头的方法。基于传感器的方法依赖于磁性和惯性属性,并给出了自我姿态的稳健估计。然而,它们需要特殊设计且难以设置的设备,并且具有限定用户一般性移动的侵入性。
基于摄像头的方法则侵入性较小,可以在不同的环境中工作。其中一类方法依靠自上而下的朝内式摄像头来获得用户的最佳视图,而另一类方法则使用窄视场前向摄像头(用户不可见)。只要能够清楚地“看到”身体部位,前一种设置可以产生可靠的结果,但朝内式摄像头需要向前延伸,以避免鼻子和脸颊被遮挡。当用户离开视场时,姿态估计将完全失败。后一种设置的优点是在看不到用户的情况下估计自我姿态,但它难以解析模糊的身体姿态,尤其是手臂姿态。
图1说明了本篇论文所希望解决的问题:目标是从以自我为中心的摄像头角度推断2D和3D姿势信息,如关节位置和旋转,这是将运动从原始用户转移到通用Avatar或收集用户姿势信息的必需项。
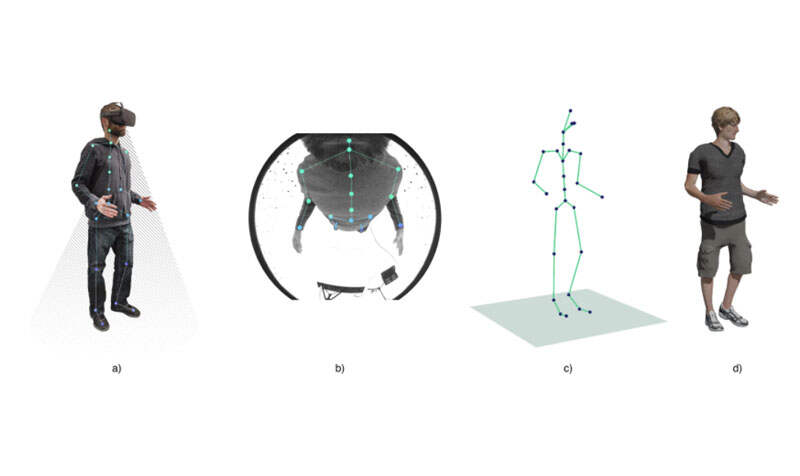
图1
团队的配置中使用的单目摄像头安装在头显边缘(如图1a所示),距离平均尺寸的鼻子大约2厘米,朝下。图2进一步显示了摄像头在不同身体配置下看到的图像。最上面一行显示了从以自中心的角度来看,什么身体部位会变得自遮挡。从亮红色到深绿色的连续渐变编码相应着色区域的像素分辨率的增加。
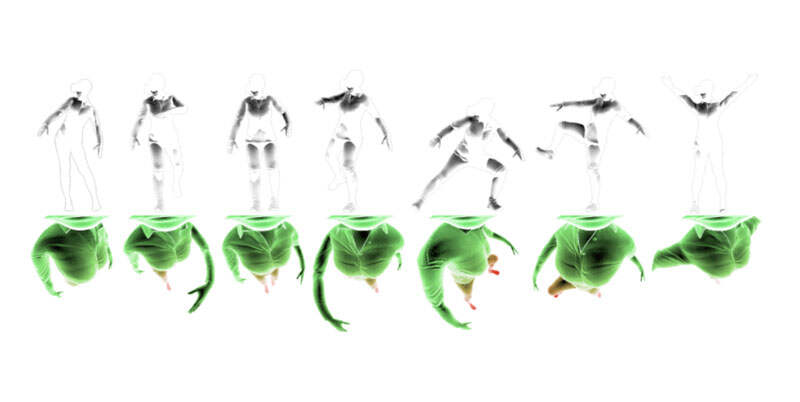
图2
上图显示了同一角色的不同姿势的可视化。最上方是从外部摄像头视点渲染的姿势。白色代表遮挡,遮挡是从以自中心角度看不到的身体部位。最下方是从以自为中心摄像头视点渲染的姿势。颜色梯度表示身体每个区域的图像像素密度:绿色表示像素密度较高,而红色表示像素密度较低。
图表说明了自中心人体姿势估计所面临的挑战:严重的自遮挡、极端的透视效果和较低的下半身像素密度。
有数个挑战导致了这个问题的困难:
- (1)由于鱼眼透镜和摄像头靠近面部,会出现强烈的透视失真。这导致图像具有强烈的径向失真,并且上半身和下半身之间的图像分辨率存在巨大差异,如图2底部一行所示。因此,从正面或360度偏航视图进行2D身体姿态估计的最先进方法在这类图像上会失败
- (2) 在许多情况下,身体会发生自遮挡,尤其是在下半身,这需要对关节位置具有很强的空间意识;
- (3) 自为中心三维身体姿态估计是计算机视觉中一个相对未探索的问题,因此公众可访问的标记数据集很少;
- (4) 正如传统的3D身体姿态估计所示,当在三维中lift二维关节位置时,存在自然模糊性。
这种不同寻常的自中心视觉表现需要一种全新的方法和全新的训练语料库,而本篇论文正是主要针对这两个问题。他们提出的全新神经网络架构编码了由不同分辨率、极端视角效应和自遮挡引起的上下身体关节之间的不确定性差异。
团队使用真实的3D注释对合成基准和真实世界基准进行了定量和定性评估,并表明所述方法的性能比以前的Mo2Cap2高出25%以上。消融研究表明,引入新型multi-branch解码器来重建2D输入热图和旋转是3D姿态估计的显著改进的原因。
架构
团队提出了用于3D姿态估计的深度学习架构。这是一种由两个主要模块组成的两步方法:i)第一个模块检测图像空间中身体关节位置的2D热图;ii)第二个模块将从前面模块生成的2D热图预测作为输入,并使用新颖的multi-branch自动编码器架构回归身体关节的3D坐标,并根据骨骼层次的局部关节旋转和重建的热图预测。
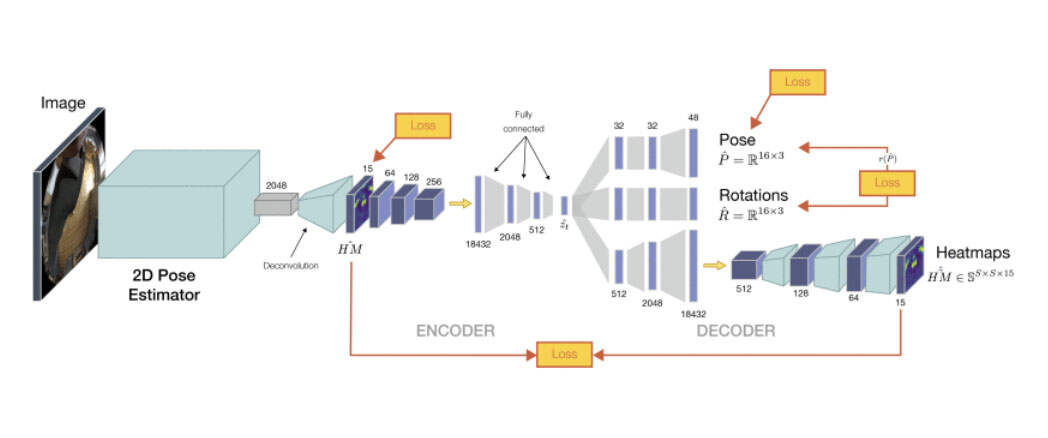
这种管道方法最重要的优点之一是,可以根据可用的训练数据独立训练2D和3D模块。例如,如果具有3D注释的足够大的图像语料库不可用,则可以使用3D mocap数据及其投影热图来独立地训练3D lifting模块。一旦对这两个模块进行了预训练,整个架构就可以端到端地进行微调,因为它完全可微分。
multi-branch自动编码器模块同时提供了具有姿势的多个表示的能力,例如关节位置和局部旋转等。所述架构的另一个优点是,第二和第三branch只在训练时需要,并且可以在测试时删除,从而保证更好的性能和更快的执行。
二维姿势检测
给定RGB图像I∈R368×368×3作为输入,2D姿势检测器推断2D姿势,表示为一组热图HM∈R47×47×15,每个身体关节一个。对于这项任务,团队已经试验了不同的标准架构,包括ResNet 50和U-Net。
他们使用归一化输入图像对模型进行训练。其中,图像是通过减去平均值并除以标准差获得。然后,他们使用ground truth热图与预测热图之间差异的均方误差作为损失:
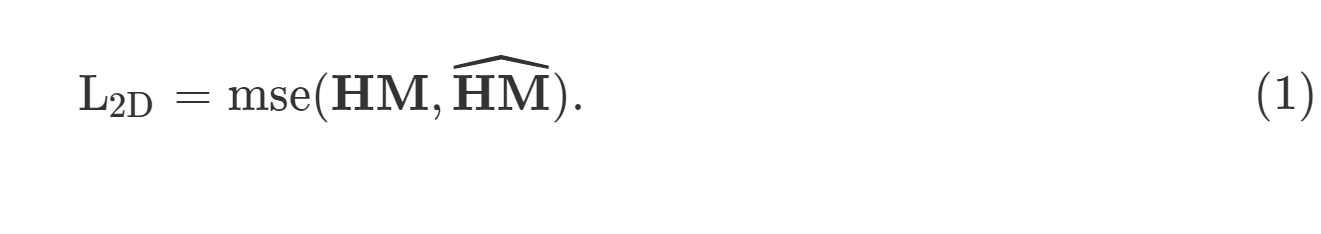
二维到三维映射
3D姿态模块将第一模块计算的15个热图作为输入,并输出最终的3D姿态P∈R16×3作为一组关节位置。请注意,输出3D关节的数量为16,因为包括头部(尽管头部在视场之外,但它可以在3D中回归)。
团队的方法从输入热图预测3D姿势,而不仅仅是2D位置。主要优点是热图携带了与2D姿态估计的不确定性相关的重要信息。
所提出的架构的主要新颖性是,确保热图表示中表达的不确定性信息不会丢失,它在姿态嵌入中得到了保留。当编码器将一组热图作为输入并将其编码到嵌入z
中时,解码器有多个branch。首先从z
回归3D姿势;2nd估计局部关节旋转(相对于父节点);以及3rd重构输入热图。所述branch的目的是迫使latent向量对估计的2D热图的概率密度函数进行编码。
自动编码器的整体损失函数表示为:
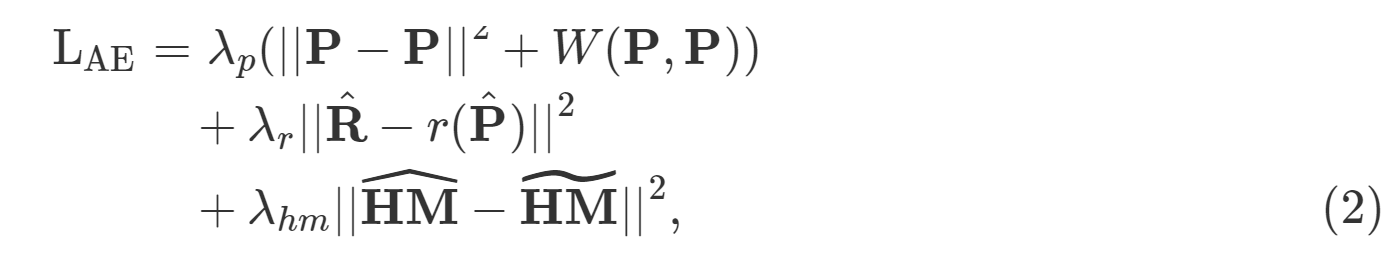
研究人员测试了不同的局部联合旋转表示,而由于训练过程中旋转的稳定性,他们最终选择了四元数表示,从而产生更稳健的模型。旋转branch同时有助于生成更好的结果,在逐帧估计的姿势上,连续帧上的过渡更平滑。
使用估计旋转的角色动画
由multi-branch自动编码器架构生成的姿态嵌入估计包含姿态的相关基本信息,这使得能够基于特定应用程序更改/添加表示。具体而言,旋转branch的引入改善了整体重建误差,如表2所示,并且它是可用于角色动画的姿势定义。

根据骨架层次,由旋转branch估计的关节旋转表示为每个关节相对于父节点的局部旋转。与原始动画相比,显示受驱动角色的示例帧如图6所示。请注意,即使对于Avatar的四肢落在摄像头视场之外的姿势,模型都能够可靠地估计正确的旋转。另外,尽管逐帧计算估计,但连续帧中的姿态之间存在时间一致性。
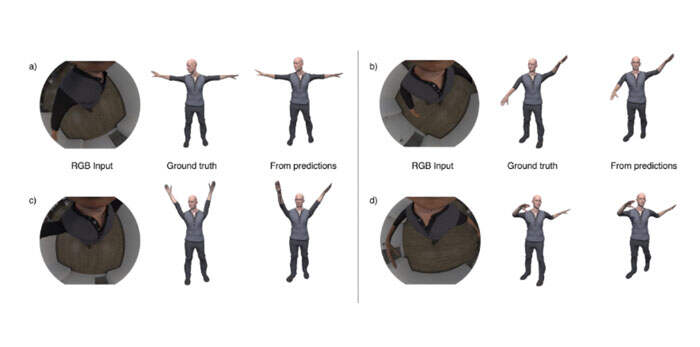
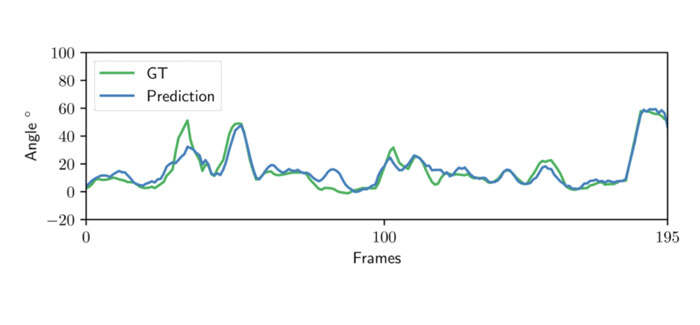
图7则显示了从输入图像估计的关节角度预测。具体来说,关节角度与ground truth一致。旋转是平滑的,网络在预测中引入了有限的“抖动”伪影。
热图估计:架构消融
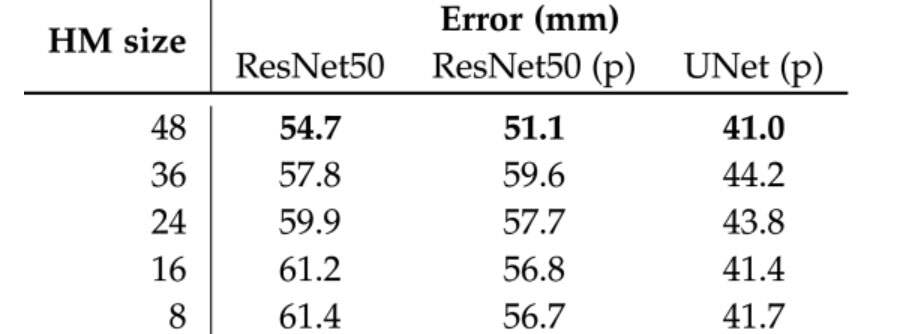
到目前为止,团队在所有实验中都使用了已建立的ResNet 50架构。为了研究热图估计网络的效果,他们对不同的架构和初始化策略进行了实验。
结果表明,预训练有帮助。与随机初始化的54.7相比,使用预训练的ResNet 50的完整管道将MPJPE误差优化至51.1 mm,见表4。

尽管有研究表明,预训练通常是不必要的,但团队指出,预训练确实可以在两个方面有所帮助。首先,预训练有助于加快收敛速度。其次,对于小型数据集,预训练有助于提高准确性。尽管他们的合成数据集很大,但与MPII等大型真实世界数据集相比,它在场景和主题方面的可变性较小。
在下一步中,研究人员使用U-Net进行2D姿态估计实验。使用U-Net架构可以提高管道的性能,并将MPJPE误差显著优化至41.0mm。
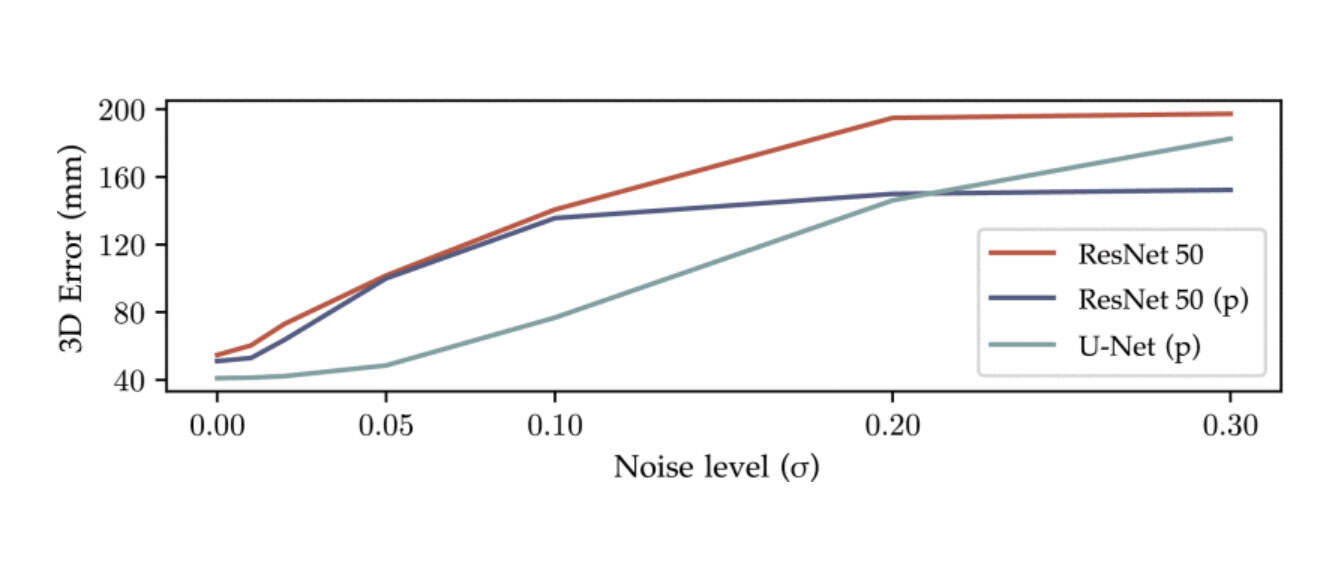
基于Resnet 50的估计器在没有事先细化的情况下失败。他们假设,改进的性能和在真实图像上观察到的行为证明了U-Net更好的泛化特性。为了支持假设,团队进行了一个额外的实验。将高斯白噪点添加到合成数据集的测试图像中,并使用不同的2D姿态估计网络来测量管道的性能。
图8绘制了不同噪点水平下的MPJPE误差。值得注意的是,基于U-Net的管道的误差增加缓慢,而基于Resnet 50的管道在小噪点水平下已经产生了大的误差。这种行为支持了假设,即U-Net架构具有更好的泛化特性。
liftIng网络:参数消融
为了验证multi-branch三维姿态lifting网络的架构设计选择,团队对两个主要参数进行了消融研究。
首先,找到嵌入z
的最佳大小,它对3D姿势、关节旋转和2D姿势的不确定性进行编码。表6列出了所有三种不同热图估计网络使用不同尺寸的z
的MPJPE误差。无论热图估计网络的选择如何,z^∈R50都能产生最好的结果。较小的嵌入会产生明显更高的误差,而较大的嵌入只会稍微影响结果。
自中心的真实数据集评估

与Mo2Cap2的比较。团队将方法的结果与直接竞争对手Mo2Cap2进行了比较,包括室内和室外序列。为了进行公平的比较,仅根据他们提供的合成训练数据来训练模型。表8报告了两种方法的MPJPE错误。
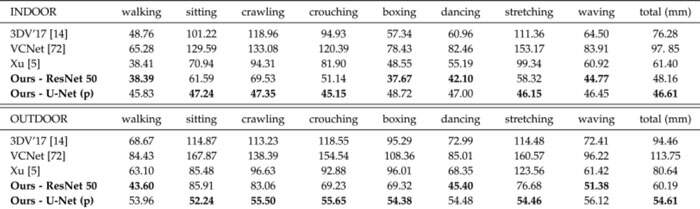
可以看出,团队的方法在室内和室外场景中都大大优于Mo2Cap2。在这里,使用在ImageNet上预先训练的U-Net模型的方法产生了最好的结果。但在室内,在更受控制的环境中,两种架构变体几乎不相上下。
团队架构的一个重要优势是,模型可以同时在3D和2D数据集的混合上进行训练:如果图像样本只有2D注释,但没有3D ground truth标签,则样本依然可以使用,只有热图会导致损失。
他们评估了在两种场景中添加带有2D但没有3D标签的额外图像的效果:自中心和前置摄像头。在自为中心的情况下,他们创建了xR-EgoPose测试集的两个子集。第一个子集包含具有3D和2D标签的所有可用图像样本的50%。

第二个包含100%的带有2D标签的图像样本,但只有50%的3D标签。实际上,第二子集包含的图像数量是仅具有2D注释的图像数量的两倍。表10a比较了子集之间的结果。可以看出,最终的3D姿态估计受益于额外的2D注释。在Human3.6M数据集上可以看到等效的行为。表10b显示了当使用来自COCO和MPII的附加2D注释时重建误差的改善。
总的来说,团队提出了一种从安装在头显的单眼摄像头估计3D身体姿势的解决方案。给定单个图像,所述方法完全可微网络估计热图,并使用它们作为中间表示,使用新的multi-branch自动编码器回归3D姿态。
这种新的架构设计是在具有挑战性的数据集中进行精确重建的基础。与竞争对手的数据集相比,准确率提高了24%以上,实验证明可以推广到更通用的3D人体姿态估计,即具有最先进性能的前置摄像头任务。
最后,他们介绍了xR-EgoPose数据集,这是一个新的大规模照片逼真的合成数据集,对训练至关重要。团队表示,增加额外的摄像头以覆盖更多的视场,并实现多视图传感是未来研究的重点。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论