
深度重建是计算机视觉中一个长期存在的基本问题。数十年来,最热门的深度估计技术是基于立体匹配或运动结构。但近来最优秀的结果来自于基于学习的方法。随着整体重建质量的提高,焦点已转移到新的领域,如单目估计、边缘质量和时间一致性。
时间一致性对于计算摄影和虚拟现实中的视频应用尤为重要,因为不一致的深度可能会导致令人反感的闪烁和游动伪影。不过,一致的视频深度估计是一个难题,即便是最好的方法都会受到场景内容的不可预测误差和缺陷所影响,尤其是在无纹理和镜面区域。另外,需要在线重建的应用程序则加剧了这一困难。
在名为《Temporally Consistent Online Depth Estimation Using Point-Based Fusion》的论文中,Meta建议使用全局点云来促使在线视频深度估计的时间一致性。他们展示了如何在未来帧未知的情况下处理动态对象和更新静态点云这两个问题。定量和定性结果表明所述方法在不牺牲空间质量的情况下显著提高了立体和单目深度估计的时间一致性。

总的来说,Meta主要提出了基于点云的融合,并用于时间一致的视频深度估计。他们提出了一种三阶段方法以促使在线设置的一致性,同时允许更新以提高重建的准确性和处理动态场景。同时,研究人员提出了一种用于动态估计和深度融合的图像空间方法,而所述方法重量轻,运行时开销低。
方法
给定具有已知姿态的RGB图像序列ct,为每个ct,t∈{0,1,2,…}估计深度图dt,使得在时间t可见的所有场景点的几何表示从t-1到t都是准确和一致的。另外,研究人员希望在线解决这个问题;在任何时刻t,未来帧di,i>t都是未知的。
准确性包含一致性,因为100%准确的重建是100%一致的,但不是相反。因此,过去的大多数深度估计方法都专注于优化重建精度。然而在实践中,很难实现完全准确的重建,所以大多数都存在不一致性。
一种增强时间一致性的简单方法是使用已知的camera姿势将深度图dt提升到3D点云,然后将其重新投影到未来的帧中。但这种基于重投影的方法存在以下缺点:它无法处理动态场景,在未遮挡的区域中产生hole,并且它会将dt中的任何错误传播到所有后续帧。
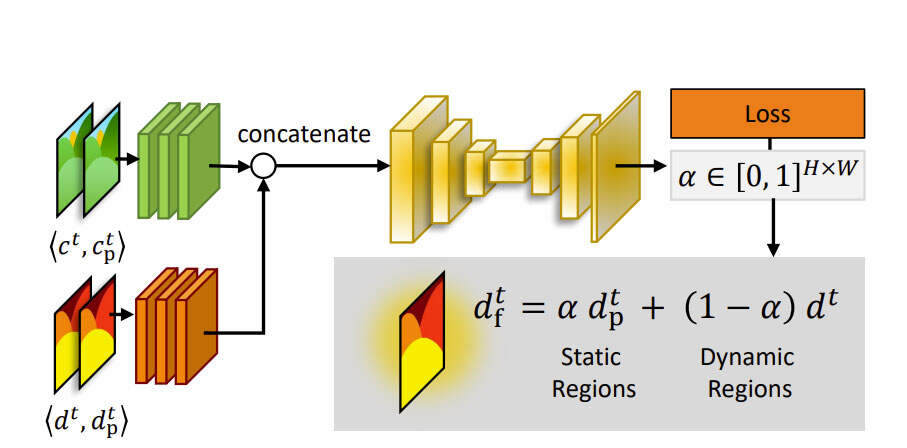
Meta提出的方法尝试利用全局点云的优势,以同时解决上述缺点。
他们分三个阶段完成:
- (i)时间融合步骤:通过将dt与图像空间中全局点云的先前深度混合,识别并更新从帧t−1变为t的场景区域。
- (ii)空间融合:恢复空间细节,并校正来自第一阶段的混合输出深度图中的任何误差。
- (iii)最后,更新全局点云以合并来自帧t的变化。
在训练过程中,团队使用样本(dt,ct,dtp,ctp)来训练时间融合网络θ(·),其中(dt,ct)是当前帧t的彩色图像和估计深度,并且(dtp,ctp)是通过重新投影从帧t−k到t的ground深度和颜色来生成。
团队只在训练过程中使用未来帧(k<0)作为数据增强技术。在推理过程中,所述方法只看到当前帧t和全局点云。θ(·)由两组三个残差层组成,然后是四层U-Net。残差层从级联的深度(dtp,dt)和级联的彩色图像(ct,ctp)中提取特征,然后将其馈送到UNet中以生成混合掩模α。
这种网络架构比Mask RCNN或光流方法简单得多,参数同时更少。除了U-Net的最后一层外,研究人员在所有层上都使用ReLU激活。由于批量归一化增加了深度相关的偏差,因此使用层归一化。使用ground truth而不是dtp的估计深度,团队希望促使在静态区域中对先前的深度(α=0)产生strong bias。这确保了θ(·)只识别由于运动而引起的变化。
在从帧t−k到t不变化的区域中,重新投影的ground truth保持最优。因此,dtf的L1损失促使α=0。对于动态对象,基于估计的深度的质量,先验深度可能是最优的,也可能不是最优的,并且网络学习合适的混合权重。Meta发现α上的二进制交叉熵(BCE)损失提高了收敛性,并使其更接近binary:
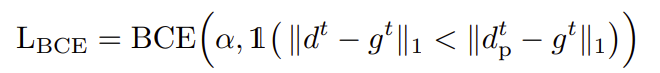
研究人员同时包括深度梯度上的L1 loss Lg和融合深度上的VGG loss。他们发现,后者比单独的L1 loss更有助于捕捉精细细节。因此,监督具有loss的时间融合网络:
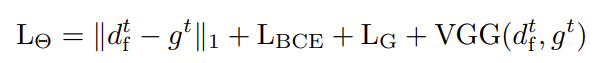
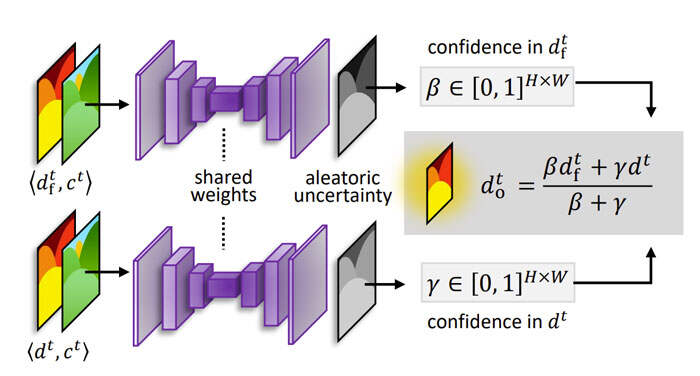
各个项分别为10、0.1、0.05和0.05。他们将深度融合网络Φ(·)实现为具有实例规范化的四层U-Net,并在所有层上激活ReLU。使用输入深度的不确定性=Φ(st dt,ct)的自监督损失来训练网络:
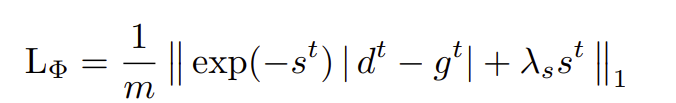
他们在FlyingThings3D数据集训练这两个网络。这包括沿随机3D轨迹移动的对象的渲染序列,并具有ground truth深度和camera姿势。为了进行微调,团队在室内环境中从自定义Blender场景渲染50个60帧序列。他们使用RAFTStereo估计dt,并使用反向深度进行训练。
这两个网络都在PyTorch中实现,并在六个Nvidia Tesla V100 GPU进行了训练。另外,研究人员在MPI Sintel数据集上评估了立体深度方法,在MPI Sintl和ScanNet数据集上分别评估了单目方法。同时,他们评估了从运动方法中学习到的结构[。
团队没有与传统的多视图立体或TSDF融合方法进行比较,因为它们存在不完整性,并且在动态场景中失败。对于每个基线,他们使用提供的预训练模型,并仅在最初测试的数据集上对其进行评估。
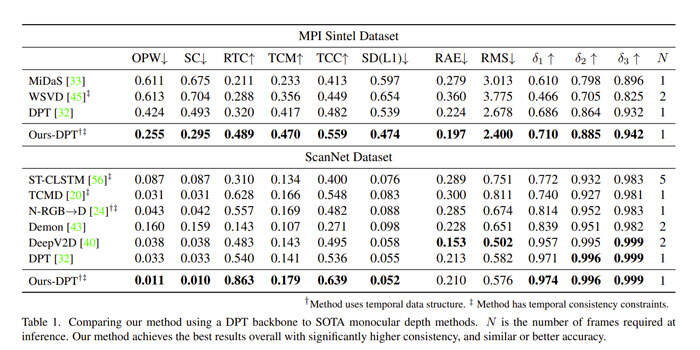
表1给出了Meta的方法和单眼基线的定量评估,图8则进行了定性比较。在这两个数据集中,团队的深度比次优方法的OPW误差低50%。直观地说,这意味着对于平均场景点,帧到帧的深度差小于其他方法的一半。

另外,Meta的深度和ground truth(TCC)的时间变化的结构相似性高出15%,这表明动态区域不是简单地跨帧平均。
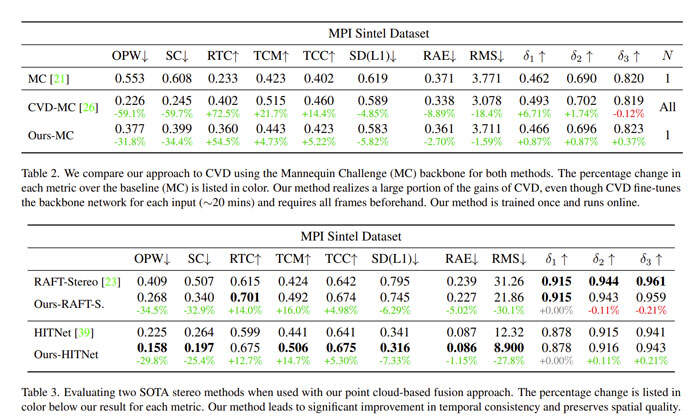
在表3中,立体方法的性能改进可以看到类似的趋势,OPW和TCC分别提高了约30%和5%。图7提供了立体结果的定性可视化。表2比较了团队方法与CVD。CVD离线运行,在推断时间微调骨干网络约20分钟。因此,它代表了时间一致性的高标准。Meta方法实现了CVD的大部分增益,同时具有可推广性和在线性。
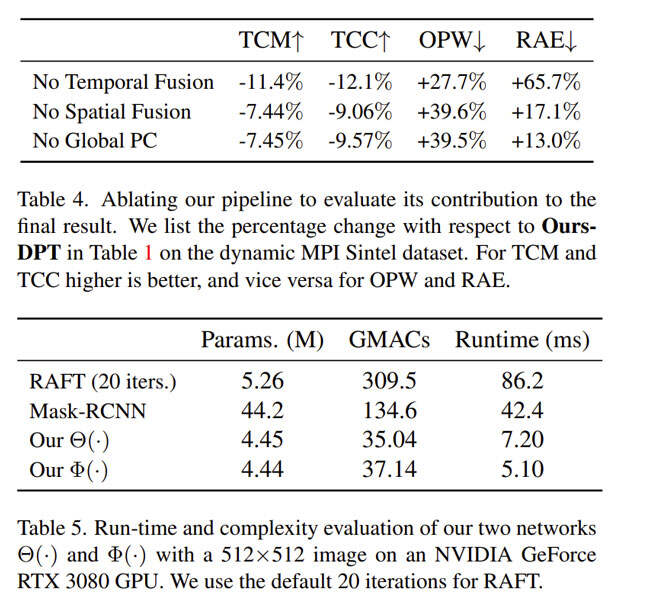
表5列出了我们两个网络的大小和运行时间,并将θ(·)与RAFT和Mask RCNN进行了比较。表4显示了消融每个阶段如何影响团队方法的性能。实验发现,时间融合阶段对一致性和准确性的影响最大。
总的来说,Meta提出了一种在线环境中时间一致的视频深度估计方法。所述方法使用全局点云,并学习图像空间融合,以促使一致性并保持准确性。尽管假设camera姿态和单眼深度的尺度已知,但可以使用点云对齐算法来计算。
为了通用性,团队的方法不假设任何特定的深度估计算法。但是,可以通过将dt的估计以重新投影的深度dtp为条件来改进结果。另外,尽管所述方法在立体设置中不使用第二视图,但除了时间一致性之外,同时可以利用左右视图一致性。对于这方面,团队将把所述方向留给未来的研究。
来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: Vicky(微信 ARC-vicky)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论