
立体视差估计是计算机视觉的基本问题之一,在AR/VR,机器人和自动驾驶等众多不同领域都有着广泛的应用。尽管研究人员在使用神经网络实现KITTI、Middlebury和ETH3D等基准的高精度方面取得了重大进展,但在端到端深度传感系统中使用立体视觉存在一系列的实际挑战。
在名为《A Practical Stereo Depth System for Smart Glasses》的论文中,Meta和Adobe的研究人员介绍了一种配备两个前置立体摄像头的智能眼镜产品系统,亦即设计一个在非常有限的计算预算下运行的端到端系统。
智能眼镜与智能手机配对,主要计算发生在手机端。端到端系统进行预处理、在线立体视觉校正和立体视觉深度估计。在校正失败的情况下,回退到单目深度估计。深度感测系统的输出然后馈送到渲染管道,以从单个用户捕获数据来创建三维计算摄影效果。
系统的主要目标是实现创建3D计算摄影效果的最佳用户体验,支持用户选择使用的任何主流智能手机,并捕获任何类型的环境。所以,它需要具有鲁棒性,并且要在非常有限的计算预算下运行。实验结果表明,团队提出的网络比其他方法快几个数量级,而且经过训练的模型取得了与最先进网络相当的性能。
总的来说,Meta和Adobe的研究人员主要设计了一个端到端立体视觉系统,介绍了一种既快速又鲁棒的新型在线校正算法,并且引入了一种新的策略来共同设计立体网络和单目深度网络,以使两个网络的输出格式相似。最后,实验证明了团队的量化网络在严格的计算预算下实现了具有竞争力的精度。
系统总览
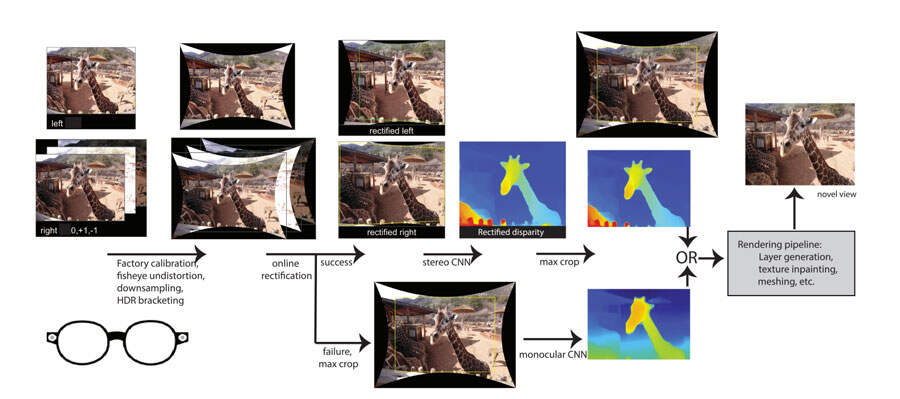
整个系统如图2所示。所述智能眼镜配备了一对分辨率为2592×1944的硬件同步鱼眼摄像头。一旦用户捕获到一个场景,图像对就传输到智能手机以接受进一步的处理。在系统中,右图像用作立体匹配的参考视图,并用于渲染新颖的视图。
在用户的智能手机端,首先将factory calibration应用于不失真的鱼眼图像,使其直线化并运行HDR bracketing。然后,将图像下采样2倍,以减少下一步的计算量。接下来,运行全新的鲁棒在线校准和校正算法。之所以需要在线校准,是因为眼镜在正常使用过程中会变形,并且外在因素可能会显著变。外在参数和内在参数同样会随着时间的推移而变化,尤其是随着热量的变化。
团队的算法根据一组精确的特征对应关系估计3-5个方位参数以及相对焦距校正。这允许对图像进行精确的校正。然而,在线校准可能会变得不可靠,例如当左摄像头被遮挡时,或者由于功能匹配数量不足。在这种情况下,转而只使用正确的图像,并通过单目深度估计网络来获得深度。
为了实现相同的downstream处理,立体和单目网络在架构输出格式方面彼此相似至关重要。因此,尽管典型的立体网络可以输出绝对视差,但这里只输出两个网络归一化为0..1的相对视差。
相对视差足以满足创建基于深度的计算摄影效果的目的。另外,共享立体网络和单目网络的编码器和解码器。研究人员同时使用共享数据集训练两个网络。其中,通过使用单目数据集渲染第二个视图来综合创建立体数据集。
在计算出视差图后,裁剪最大有效区域,以保持原始的纵横比。最后,将右侧摄像头的预测视差和相应的彩色图像传递到渲染管道,以创建最终的三维效果。
在线校正
双视图立体算法通常假设校正后的图像对作为输入。对于固定立体视觉装置,可以通过factory calibration进行校正。然而,团队提出的智能眼镜是由可以经历显著弯曲的材料制成的(>10◦ )。用户头部尺寸的变化以及焦距随温度的变化进一步加剧了这种情况。这几乎总是导致立体视觉的校准参数不完美,而不完美的校正会严重影响性能,尤其是在高频区域和近水平图像特征。
为了产生精确校正的立体对,有必要进行在线校准。研究人员通过一组在原始鱼眼图像中计算的精确特征对应来实现这一点。图3显示了将所述方法应用于真实图像对的结果。
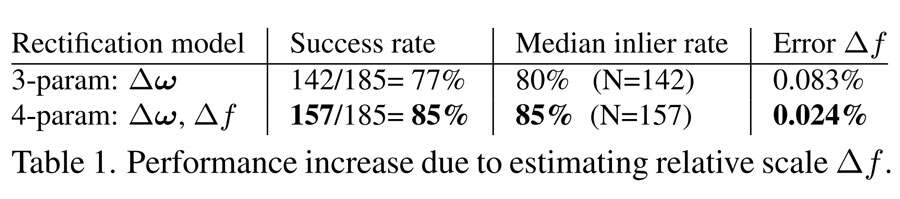
基本思想是将这个校正问题建模为每个摄像头的校正旋转ω0,ω1的估计,保持基线固定。由于绝对尺度未知,所以需要估计5个参数。现有公式固定基线的长度,并估计其方向或简单地保持tx恒定。在这里,团队采用了一种更简单的、对称的方法:在重新校正之前和之后,保持世界坐标系与立体装置对齐,将基线的长度定义为b=1,并计算两个摄像头的旋转校正。
除了5个参数外,研究人员同时估计了第6个相对尺度进行建模的参数∆f,即焦距f0/f1=1+∆f的微小变化。在实践中,他们发现补偿相对尺度非常重要,因为焦距会随着温度的变化而变化。表1说明了相对尺度的重要性。
单目和立体网络的共同设计
研究人员描述了一种共同设计立体和单目深度网络的新方法,其目标是具有一致的输出格式(相对视差)、重量轻且尽可能准确。

立体网络:团队设计了一个具有下列组件的立体网络:一个用于独立于输入立体对提取多分辨率特征的编码器;通过余弦距离比较左右特征距离的三维cost volume;将参考图像的cost volume和图像特征作为输入,并聚合视差信息的多个中间层(因为中间层直接从cost volume和参考图像中获得信息,所以当立体匹配线索较弱或不存在时,它们可以更好地利用单目深度线索);以及一种用于预测输出视差图的coarse-to-fine解码器。其中,输出视差图具有与输入右图像相同的分辨率。每个解码器模块组合较低分辨率解码器模块的输出和相同分辨率中间层的输出。图4显示了立体网络的架构图。
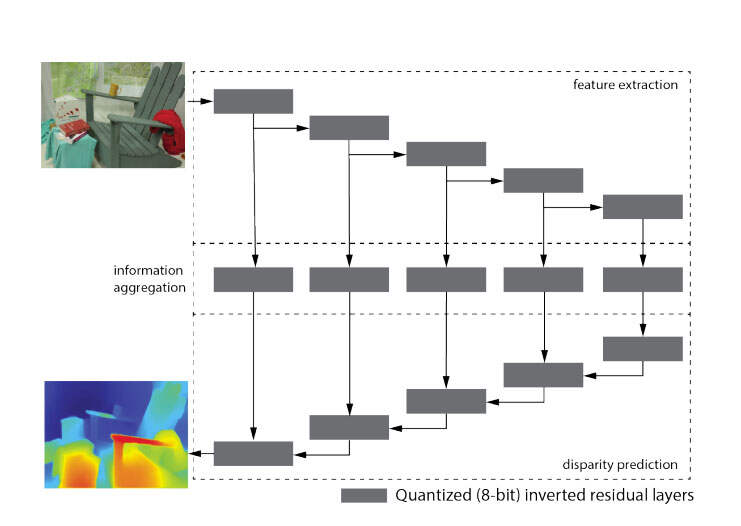
单目网络:团队设计了一个由三个组件组成的单目深度估计网络:用于提取多分辨率图像特征的编码器;用于聚合深度信息的中间层;以及用于预测视差图的coarse-to-fine解码器。图5显示了相关架构图。
共享网络组件:单目网络的所有三个组件存在于立体网络中。立体网络具有额外的cost volume模块,以明确地比较左右局部特征之间的相似性。因此,团队建议在两个网络之间共享完全相同的编码器、中间层和解码器。对于立体视觉,编码器运行两次以独立地提取左右图像特征。为了训练具有共享组件的网络,研究人员首先训练单目深度网络,然后用来自单目网络的训练权重初始化立体网络,并用立体训练数据进行微调。两个网络都以相同的loss进行训练。
这种设计允许单目和立体网络都能够输出相对视差图,并最大限度地提高预测的一致性。为了提高效率,研究人员对所有层使用MobileNetV2中提出的反向残差模块,并将权重和激活量化为8位。只有输出层和计算成本量的层没有量化。他们保持输出层32位以获得亚像素分辨率,并避免3D效果中的量化伪影。
研究人员完全从iPhone捕获的4M单眼数据集中获得立体数据。使用来自单目数据集的嵌入式深度图,他们根据智能眼镜的已知焦距和基线渲染第二个视图。被遮挡的区域同样会修复。团队指出,这使得所提出的立体数据集比任何现有的训练数据集都更加多样化。另外,立体和单目网络都可以用相同的数据进行训练,以确保它们的输出和行为相似。
为了令训练数据对立体网络具有照片真实性,研究人员对渲染的立体数据集进行数据增强,包括亮度、对比度、色调、饱和度、jpeg压缩、反射增强和图像边界增强等等。
新颖视图合成
团队使用基于LDI(分层深度图像)的方法来创建立体训练数据集以及创建所需3D效果。给定一个图像/深度对,将其提升为分层深度图像,通过进行LDI修复来产生被遮挡的几何体的幻觉,并最终将其转换为纹理网格。对于立体数据集的创建,使用单目背景深度和彩色图像来创建这样的网格并渲染第二个视图。对于3D效果,使用立体系统的预测和预定义的轨迹来生成新颖视图的平滑视频。
神经网络实现细节
研究人员使用了高效单目网络Tiefenrausch。立体网络Argos与Tiefenrausch共享相同的编码器、中间层和解码器,但增加了cost volume模块。
对于production模型,团队首先使用iPhone数据集重新训练Tiefenrausch。他们将预测的视差图与ground truth视差图与MiDaS median aligner对准,以输出相对视差。当计算loss时,对预测和ground truth进行2×2次采样来计算L=5 level的梯度损失。然后,使用Tiefenrausch权重初始化立体网络Argos。
除了一个层(cost volume之后添加的层)之外的所有层都可以用Tiefenrausch权重初始化。然后,使用渲染的iPhone立体数据集对Argos进行微调。在微调过程使用Adam优化器。他们总共训练了640k次迭代,并在PyTorch中使用量化感知训练(QAT)。PTQ(训练后量化)导致精度显著下降。他们在第2000次训练迭代时开始QAT,并使用FBGEMM后端。所有输入图像的大小都调整为384×288分辨率以用于训练和评。
为了将模型与SotA模型进行公平比较,仅使用Sceneflow数据集(FlyingThings3D、Driving和Monkaa)训练Argos的另一个版本,并将结果与同样在Sceneflow训练的其他SotA模型相比较。
团队在三星Galaxy S8 CPU运行了管道基准测试。校正管道需要300-400ms,立体网络大约需要965ms。管道的其他部分总共花费的延迟比这两个步骤低得多。所提出的模型针对移动CPU进行了优化,但将SotA模型转换为移动友好格式并非易事,同时没有太大意义,因为它们不是为移动而设计。
作为折衷方案,他们将所有模型在计算机服务器机器的运行时间与Intel(R)Xeon(R)Gold 6138 CPU@2.00GHz进行了比较,如表2所示。表2和图6显示了所述方法与几种SotA立体方法的定量比较。
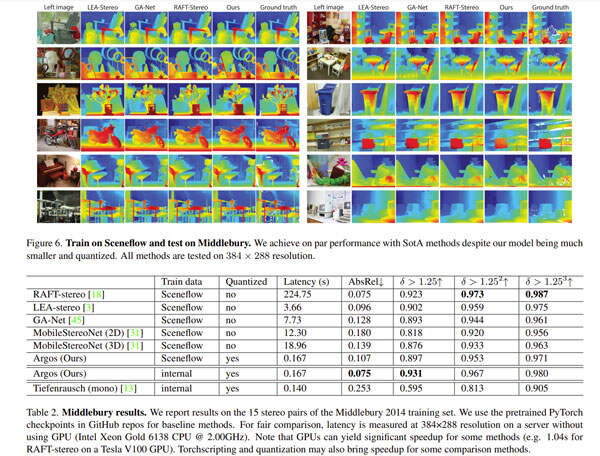
当使用Sceneflow数据集进行训练时,团队提出的方法实现了与SotA方法相当的性能,而速度快了几个数量级。使用渲染的内部立体数据集进行训练可以进一步提高了性能,并在所有测试模型中实现了最佳的绝对相对误差。
他们同时包括在了在内部数据集重新训练的Tiefenrausch的结果。与Tiefenrausch相比,立体模型Argos将绝对相对误差从0.253显著降低到0.075,这表明了从单目数据集渲染立体数据集以训练模型的有效性。
值得注意的是,团队的目标是设计一个在所有场景中都能稳定工作的端到端深度系统,而不是在Middlebury等学术基准上实现最佳性能。特定设计选择(例如使用反射增强)可能会导致Middlebury的精度下降。
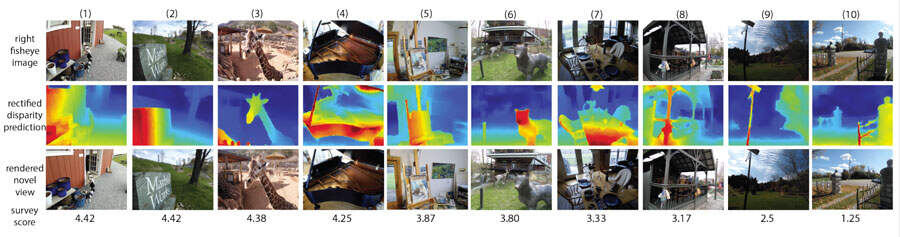
为了更好地了解深度系统的质量,研究人员对24名参与者被试进行了调查。他们从智能眼镜中捕获了大量场景,然后用深度系统中的深度映射渲染新颖视图视频。他们要求参与者对渲染视频的质量进行评分,从1到5,其中5最好(没有伪影),1最差(主要伪影)。
在所有回答中,立体深度的平均得分为3.44,使用单目深度的平均得分是2.96。图7显示了10个调查场景,涵盖了成功和失败的案例。
一个有趣的观察结果是,深度映射质量有时与渲染的新颖视图视频的质量不直接相关。例如,场景(4)的深度图很差,但渲染视图中的伪影很少,用户给出了很高的分数。相比之下,(10)的深度图除了围栏结构之外基本正确。然而,渲染的视频在围栏附近有刺眼的伪影,导致调查中的用户评分很低。
总的来说,Meta和Adobe的团队提出了一种在智能手机高效运行的端到端立体深度传感系统设计。他们同时描述了一种新的在线校正算法,一种单目和立体视差网络的新颖联合设计,以及一种从单目数据集导出大型立体数据集的新方法。另外,研究人员提出了一种8位量化立体模型,而与最先进的方法相比,所述模型在标准立体基准上具有竞争力。
在国内AR硬件厂商中,首镜科技拥有AR设备的显示、硬件、交互、驱动软件等核心技术,产品具备增强显示、环境感知、指战交互、智能识别等功能,为使用者在应用中获得实时的数据支持,建立视觉和听觉的数字环境。公司专注于B端市场,深耕垂直行业,满足定制化需求,产品及解决方案服务于工业、安防、文旅、教育等多领域,赋能行业、助力AR技术落地应用。

来源:映维网
投稿:tougao@arinchina.com
稿件/商务合作: 向前(微信 Shixiangqian7)电话:18700987744
创始人:张明军(微信 13720775110)
更多精彩内容,请关注ARinChina微信公众号(ID:X增强现实)



评论