
根据二维图像数据进行动态三维对象和场景的图像真实感绘制是计算机视觉和图形学领域的一个研究热点。近年来,基于学习的方法获得了令人印象深刻的实证结果。受其推动,体三维表示在图形社区重新引起了人们的兴趣。利用诸如深度神经网络这样的泛型函数逼近器,相关方法通过直接监控原始图像像素来获得令人信服的结果。所以,它们避免了分配几何和辐射特性这一通常非常困难的任务。利用体三维模型固有的简单性,众多研究致力于扩展小幅运动建模方法、光照变化、减少数据需求,以及学习效率等。
尽管在体三维模型方面取得了进展,但它们依然需要做出权衡;要么内存占用量大,要么渲染的计算开销大。巨大的内存占用极大地限制了所述方法的分辨率,并导致高频细节的缺乏。另外,高计算成本限制了对实时应用的适用性,例如VR临场感。理想的表示应该是内存效率高、渲染速度快、可驱动且具有较高的渲染质量。

Neural Volumes是一种用于学习、渲染和驱动动态对象的方法(动态对象使用外向内摄影头装备捕获)。由于统一的体素网格是用来模拟场景,这一方法适用于对象,而不是场景。由于场景的大部分都是由空的空间组成,所以Neural Volumes使用一个扭曲场来最大化可用分辨率的效用。然而,这种方法的有效性受到扭曲分辨率和网络以无监督方式学习复杂逆扭曲的能力的限制。
Neural Radiance Fields(NeRF)则使用紧凑表示法解决分辨率问题。另外,NeRF只处理静态场景。另一个挑战是运行时,因为多层感知器(MLP)必须沿着camera光线在每个采样点进行评估。要合成单个高分辨率图像,这将导致数十亿次MLP评估,导致渲染时间非常慢,大约每帧30秒。
简单来说,三角形网格很难对头发等薄结构进行建模。在合理的内存预算下,Neural Volumes等体三维表示的分辨率太低,而Neural Radiance Fields等高分辨率隐式表示的实时应用速度太慢。
针对这个问题,谷歌和哈佛大学组成的团队基于专门用于处理采样和混叠的NeRF变体mip-NeRF提出了一种相关的扩展。名为mip NeRF 360的模型主要利用非线性场景参数化、online distillation和一种基于失真的正则化器来克服unbounded场景带来的挑战。与mip NeRF相比,团队的均方误差降低了54%,并且能够为高度复杂的unbounded真实世界场景生成逼真的合成视图和详细的深度映射。
将NeRF-like模型应用于大型unbounded场景会引发三个关键问题:
- 参数化:unbounded 360度场景可以占据任意大的欧氏空间区域,但mip NeRF要求将3D场景坐标映射到bounded域。
- 效率:大而详细的场景需要更多的网络容量,但在训练期间沿着每条光线密集地查询更大的MLP非常昂贵。
- 模糊性:unbounded 360度场景的背景区域由比中心区域稀疏得多的光线描述。这加剧了从2D图像重建3D内容的固有模糊性。
所以,mip NeRF 360主要针对上述三个问题进行应对和优化:
1. 场景和光线参数化
尽管之前已经存在关于unbounded场景点参数化的研究,但它们并不能为mip-NeRF环境提供解决方案。在团队针对的环境中,其必须重新参数化高斯。
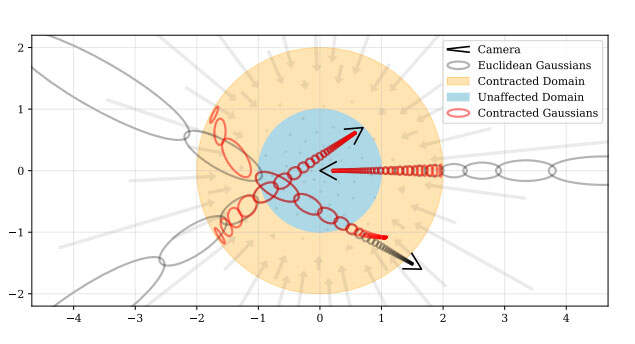
上图是场景参数化的二维可视化。团队定义了一个contract(·) operator,它可以将坐标映射到半径为2的球体(橙色),其中半径为1(蓝色)的点不受影响。研究人员将这种收缩应用于欧几里德3D空间中的mip-NeRF高斯(灰色椭圆),类似于卡尔曼滤波器来产生收缩高斯(红色椭圆),其中心保证位于半径为2的球内。contract(·)的设计与根据视差线性划分光线间隔的选择相结合,意味着从位于场景原点的camera投射的光线在橙色区域具有等距间隔。
这意味着,不仅初始样本在视差上呈线性分布,而且各个间隔的后续重采样将以类似的方式分布。从图2可以看出,光线样本的线性视差间隔抵消了收缩contract(·)。本质上,团队将场景坐标与反向深度间距共同设计,这提供了unbounded场景的参数化,一种非常接近于NeRF的高效设置:在bounded空间内均匀分布的光线间隔。
2. Coarse-to-Fine Online Distillation
mip NeRF使用从Coarse-to-Fine的重采样策略,其中使用“coarse”射线间隔和“fine”射线间隔对MLP进行一次评估,并使用两次扫描的图像重建损失进行监督。相反,团队训练了两个MLP,一个““proposal MLP”Θprop和一个“NeRF MLP”ΘNeRF。proposal MLP预测体积密度,但不预测颜色。
关键的是,proposal MLP产生的权重没有经过训练以再现输入图像,而是训练成约束NeRF MLP产生的权重。这两个MLP都是随机初始化并联合训练,所以这种监督可以认为是NeRF MLP的知识蒸馏到proposal MLP中的一种“Online Distillation”。
3. 区间模型的正则化
由于不适定性,训练的NeRF经常表现出两种特征性的伪影:“floaters” 和“background collapse”,如下图所示。
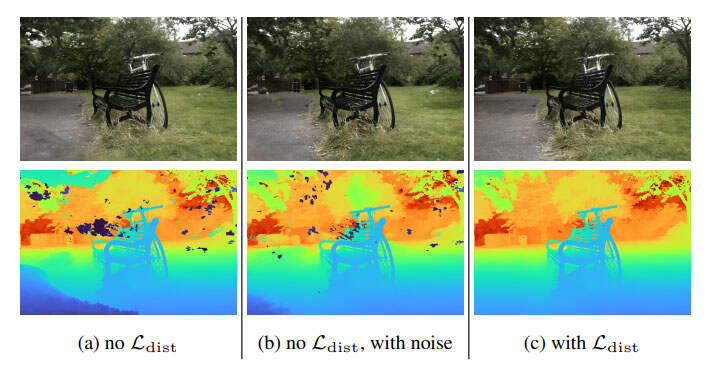
“floaters”是指体积密集的空间中不相连的小区域。从另一个角度看,它们看起来像模糊的云。“background collapse”则是远处的表面错误地建模为camera附近密集内容的半透明云。
团队通过阶跃函数来解决所述问题。
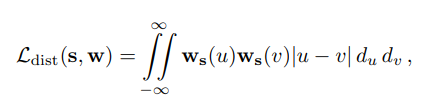
其中,一组光线距离和权重定义阶跃函数。这种损失主要通过:1)最小化每个间隔的宽度;2)将远处的间隔拉向彼此;3)将权重合并到单个间隔或附近的少量间隔中;以及4)尽可能将所有权重推向零来鼓励每条光线尽可能紧凑。
经过优化后,团队评估比较了所述方法。结果显示,与mip NeRF相比,团队的均方误差降低了54%,并且能够为高度复杂的unbounded真实世界场景生成逼真的合成视图和详细的深度映射。
当然,团队坦诚,尽管mip NeRF 360的表现明显优于mip NeRF和其他之前的研究,但它并不完美。例如,薄结构和细节可能会被忽略,比方说自行车场景中的轮胎轮辐,或者树桩场景中的树叶纹理。另外,如果camera远离场景中心,视图合成质量可能会降低。而且,类似于大多数NeRF模型,恢复场景需要在加速器上进行数个小时的训练。



评论